Abstract
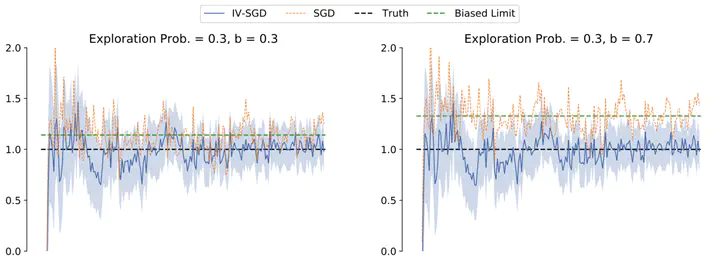
In the standard data analysis framework, data is collected (once for all), and then data analysis is carried out. However, with the advancement of digital technology, decision-makers constantly analyze past data and generate new data through their decisions. We model this as a Markov decision process and show that the dynamic interaction between data generation and data analysis leads to a new type of bias—reinforcement bias—that exacerbates the endogeneity problem in standard data analysis. We propose a class of instrument variable (IV)-based reinforcement learning (RL) algorithms to correct for the bias and establish their theoretical properties by incorporating them into a stochastic approximation (SA) framework. Our analysis accommodates iterate-dependent Markovian structures and, therefore, can be used to study RL algorithms with policy improvement. Furthermore, we derive a sharper trajectory concentration bound: with a polynomial rate, the entire future trajectory of the SA iterates, after a given finite time, falls within a ball centered at the true parameter and shrinking at another polynomial rate. We also provide formulas for inference on optimal policies of the IV-RL algorithms. These formulas highlight how intertemporal dependencies of the Markovian environment affect the inference.
Xiaowei Zhang
Associate Professor
My research research focuses on methodological advances in stochastic simulation and optimization, decision analytics, and reinforcement learning, with applications in service operations management, financial technology, and digital economy.